Parte 1: Introducción a la clasificación de contenido con Machine Learning

Cazando oportunidades
Normalmente mi trabajo consiste en hacer automatizaciones con macros (VBA y Apps scripts), hacer dashboards (Looker studio, Power BI), buscar nuevas formas de hacer las cosas o pensar en cómo ofrecerle más valor a nuestros clientes. Pero están surgiendo oportunidades súper interesantes donde poder aplicar todo ese contenido que he estado estudiando e investigando (porque soy un poco friki y esto más que trabajo es mi hobby, no os voy a mentir). Aunque nunca he estudiado las bases de Python, SQL o matemáticas, sí que he hecho proyectos personales de todo tipo pero… toca ponerse serios y bajar al barro (de hecho, por eso nace este blog).
Business case
Para hacerlo más sencillo, vamos a trabajar sobre un business case. Imagina que tienes una librería online con miles de libros que constantemente se actualizan y necesitan ser clasificados en categorías como “Ficción”, “No ficción”, “Ciencia”, “Fantasía”, etc. Hacer esto con, por poner un ejemplo, 400 o 600 libros cada mes es una tarea un poquito aburrida, y es aquí donde el Machine Learning se convierte en tu mejor amigo. Utilizando datos como el “Título” y la “Descripción” de cada libro, podemos entrenar un modelo que aprenda a clasificar automáticamente los nuevos libros. Esto no solo ayuda a ahorrar tiempo, sino que incluso podríamos llegar a montar un sistema de recomendación de libros para los usuarios.
Algoritmos de clasificación
Para tareas de clasificación como la de nuestra librería online, los algoritmos más usados se agrupan en lo que viene a ser supervised learning o aprendizaje supervisado. Es una categoría de machine learning que usa conjuntos de datos ya etiquetados o categorizados para entrenar algoritmos que te permitan predecir resultados y reconocer patrones.
Existen diferentes algoritmos de clasificación pero los más usados diría que son los siguientes:
- Naive Bayes: Rápido y efectivo, bueno para datasets simples.
- Regresión logística: Fantástico para entender probabilidades y asignar categorías.
- Árboles de decisión y Random forest: Son muy buenos para explorar las características que más influyen.
- Support Vector Machine (SVM): Funcionan extremadamente bien con datasets de texto y son conocidos por su precisión.
- Redes neuronales: Cada vez se usan más para clasificar texto, pero requieren muchos recursos.
Antes de que cualquiera de estos algoritmos puedan trabajar, necesitamos preparar los datos. Aquí es donde entra en juego el TF-IDF, una técnica fundamental para transformar el texto en un formato que los algoritmos puedan entender.
TF-IDF: Entendiendo y ponderando palabras
TF-IDF (Term Frequency-Inverse Document Frequency) es una técnica de preprocesamiento de datos que es clave en la clasificación de texto porque asigna un peso a cada palabra según su importancia. Si eres como yo, que no tienes ni papa de matemáticas (soy graduado en Relaciones Laborales y Recursos Humanos), no te preocupes. Voy a explicarlo de la manera más sencilla posible.
- Term Frequency (TF) El TF mide cuántas veces aparece una palabra (la frecuencia) en un documento específico. El cálculo se hace dividiendo el número de veces que una palabra aparece en un documento por el número total de palabras en ese documento. Cuando hablo de documento me refiero a, por ejemplo, la descripción de un libro. Si el dataset tiene 1.000 libros, tendríamos 1.000 documentos.
Fórmula:
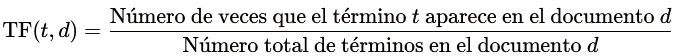
Ejemplo:
Supongamos que tenemos la descripción de un libro: “Data Science con Python”.
- Total de palabras = 4
- Frecuencia de “Data” = 1
- Frecuencia de “Science” = 1
- Frecuencia de “con” = 1
- Frecuencia de “Python” = 1
Entonces, para la palabra “Python”:
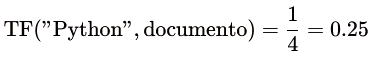
- Inverse Document Frequency (IDF): El IDF mide la importancia de una palabra en el conjunto de todos los documentos (de todo el dataset). Si una palabra es muy común (aparece en multitud de documentos), entonces su IDF será bajo, ya que no aporta mucho información para distinguir documentos.
Fórmula:

Aquí el numerador es el número total de documentos. El +1 en el denominador evita divisiones por cero.
Ejemplo:
Supongamos que tenemos 10 documentos y la palabra “Python” aparece en 3 de ellos.
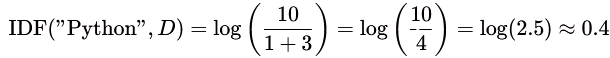
- TF-IDF Score: Por último, multiplicamos para conseguir el peso final que refleja la relevancia de una palabra en un documento específico, considerando su importancia global.
Fórmula:

Ejemplo:
Usando los valores calculados:
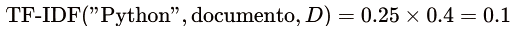
Nos da un peso de 0.1 en ese documento lo que significa que la palabra “Python” aunque aparezca en el texto, no es tan rara en el contexto global de nuestro dataset.
¿Por qué es importante TF-IDF?
En nuestro business case de la librería, TF-IDF nos ayuda a identificar qué palabras en el título y descripción de los libros son útiles para distinguir una categoría de otra. Esto es la clave cuando después pasamos esta representación a un algoritmo de clasificación como el Support Vector Machine (SVM), que utilizaremos para construir el modelo final. En la próxima parte de esta serie, entenderemos (o al menos lo vamos a intentar) cómo funciona el algoritmo SVM y qué debemos tener en cuenta.